PKS 1510-089
Summed Photon Counting Image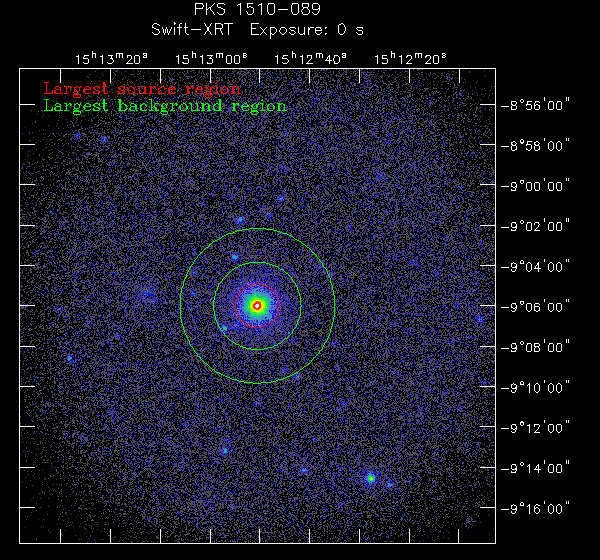 |
Upcoming Monitoring Observations
|
|
No observations are currently scheduled for this source through our monitoring program, but there may be other ToO programs that have upcoming observations on this source.
|
External Links
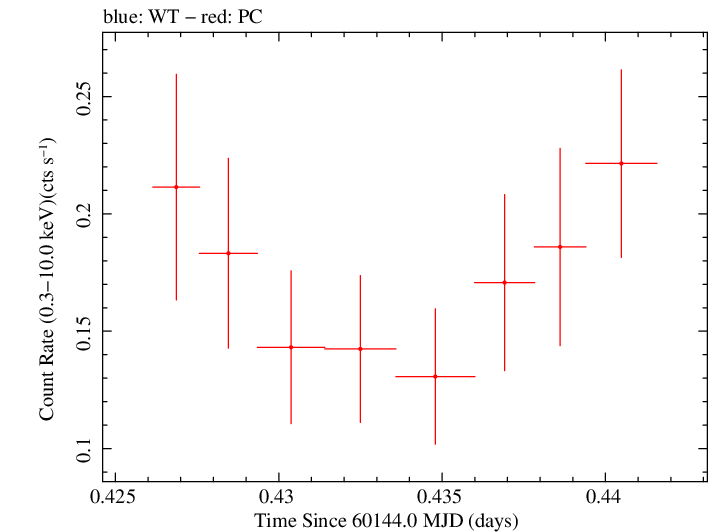
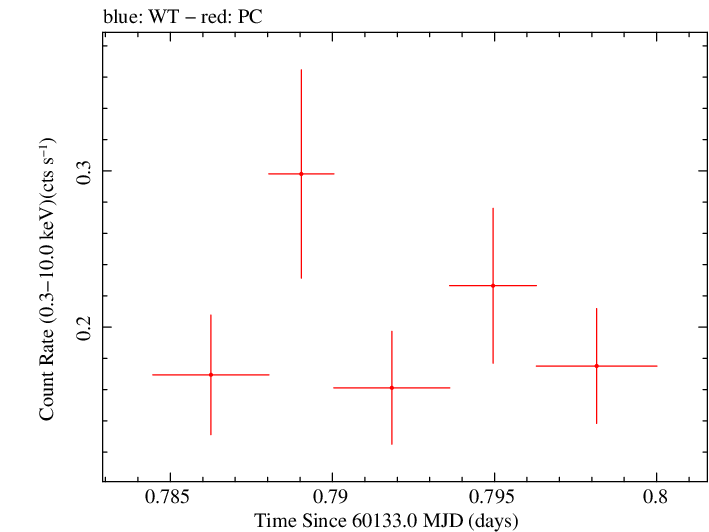
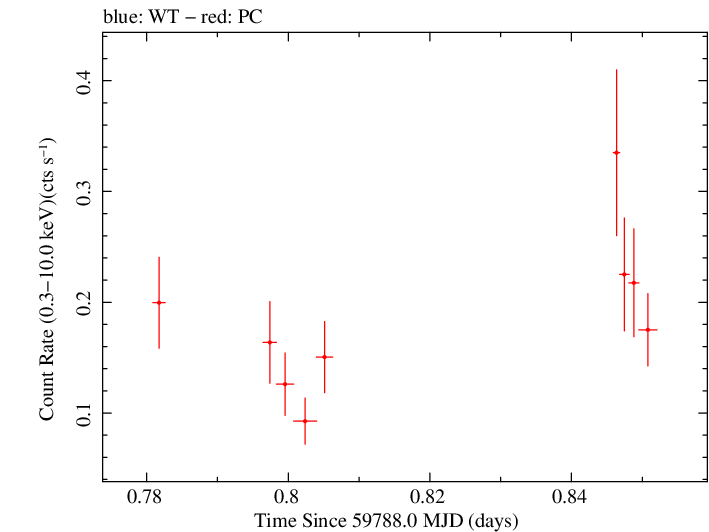
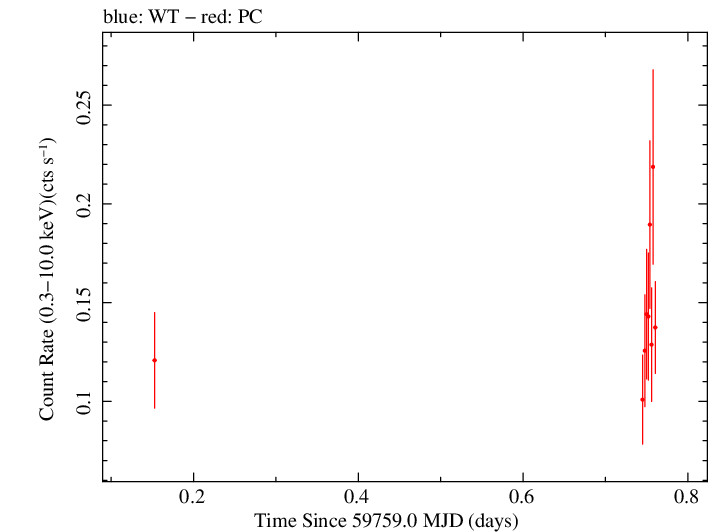
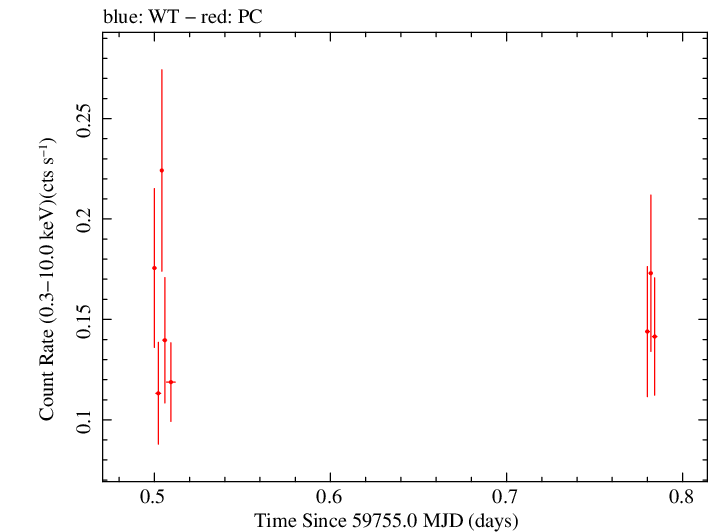
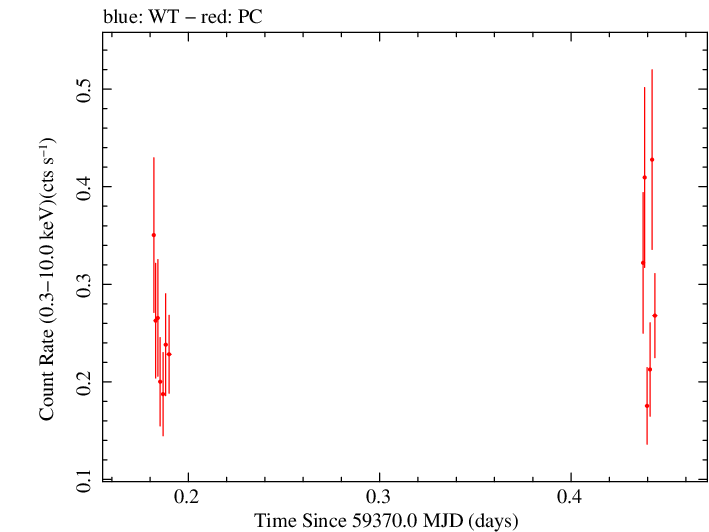
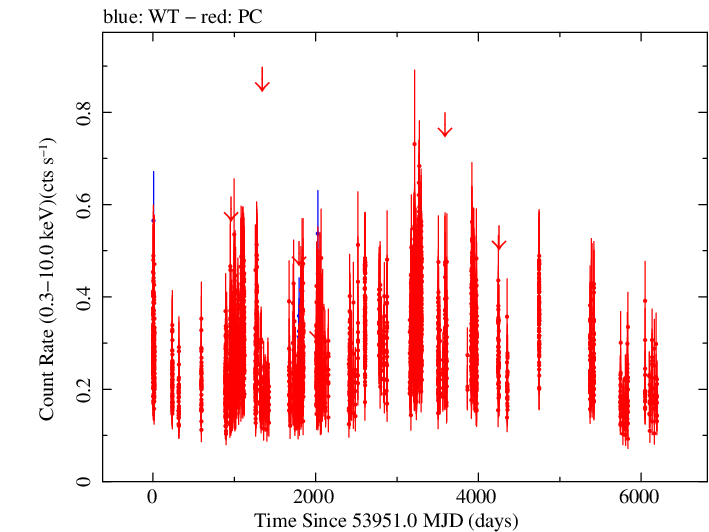
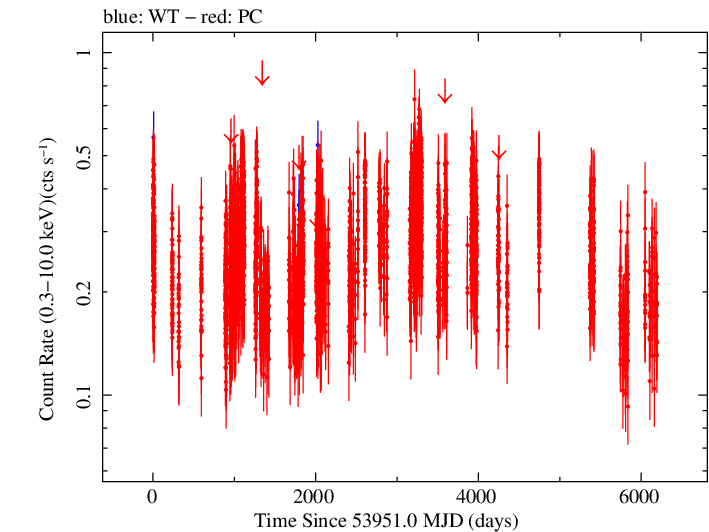
Overall Light Curves
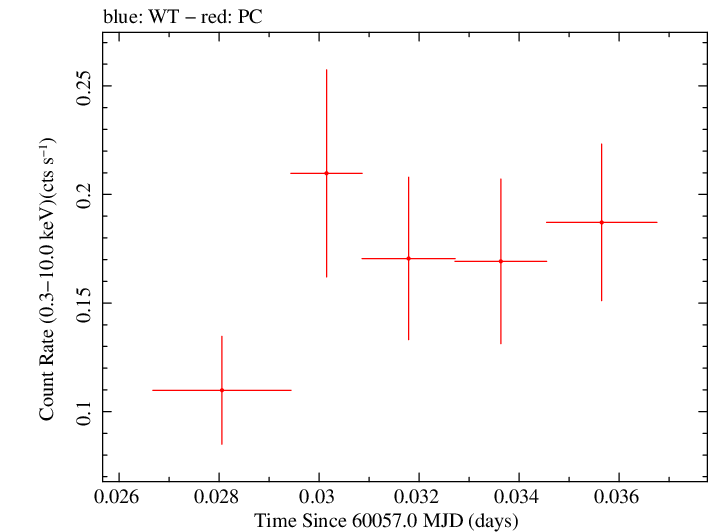
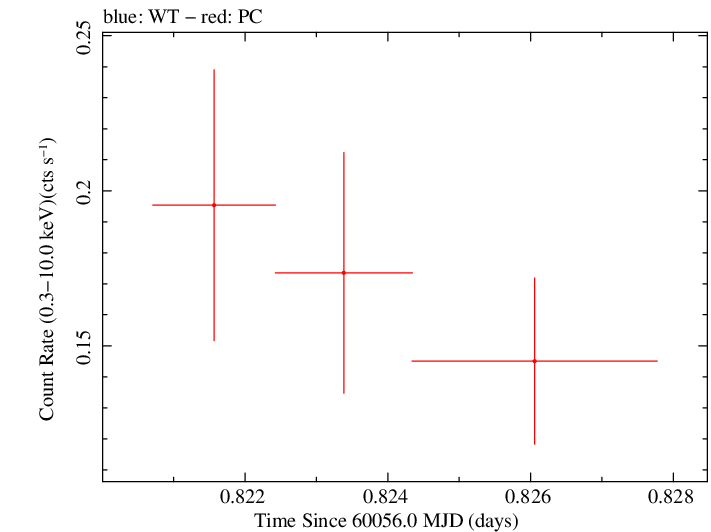
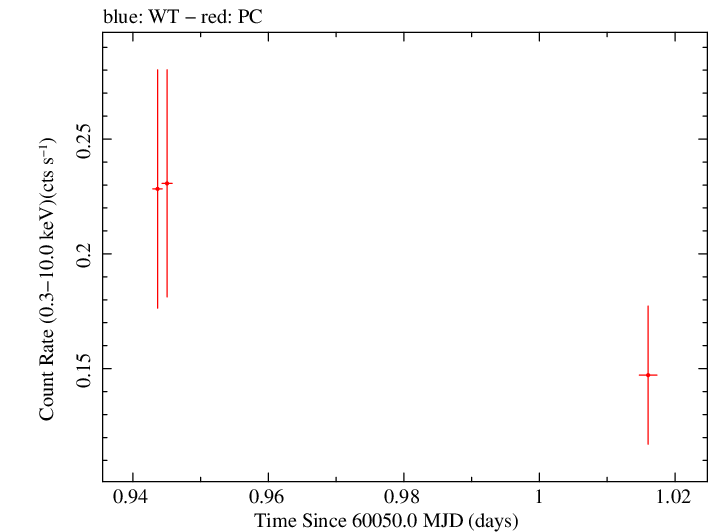
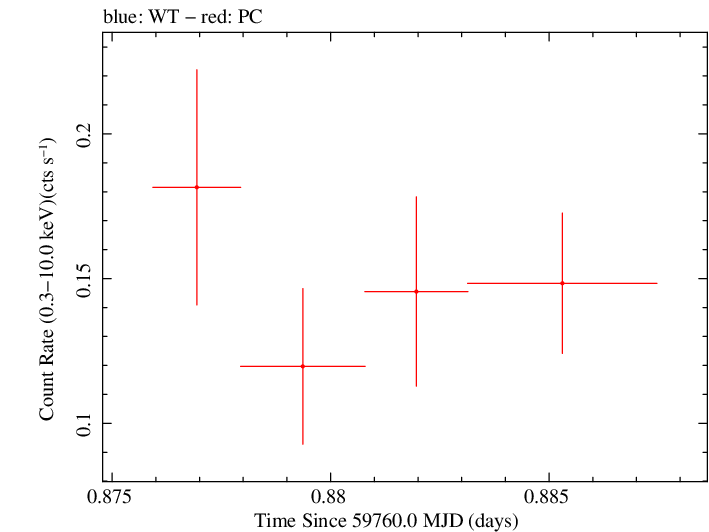
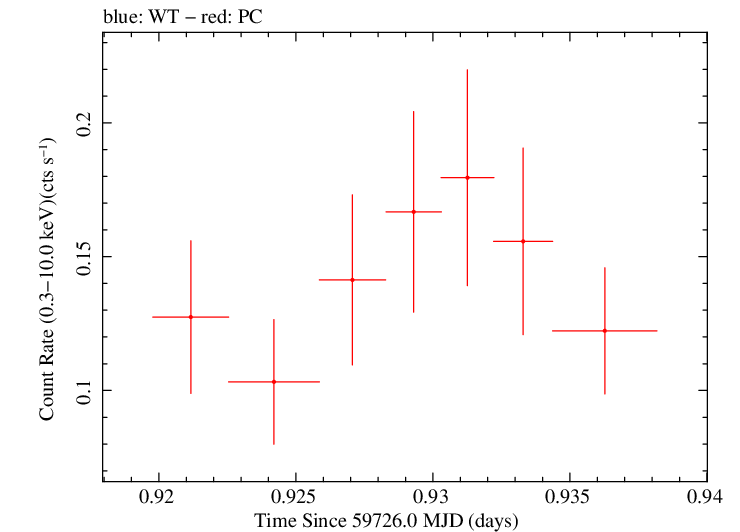
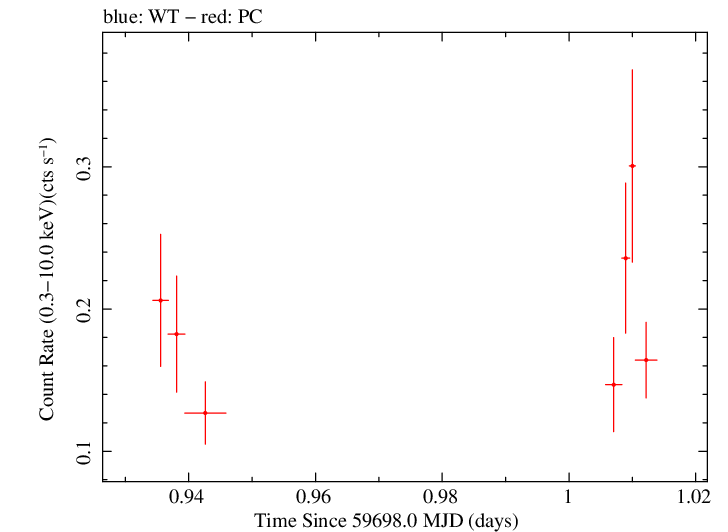
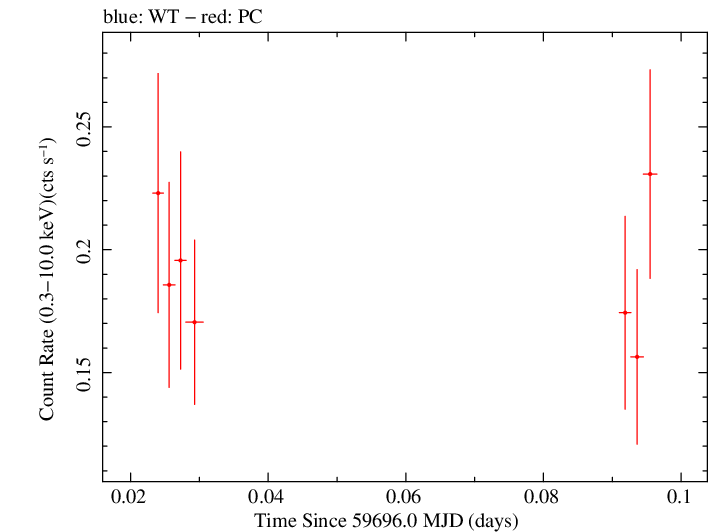
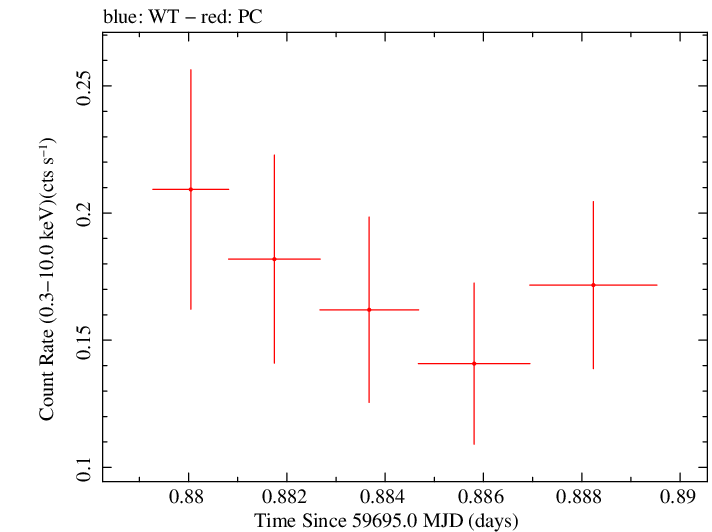
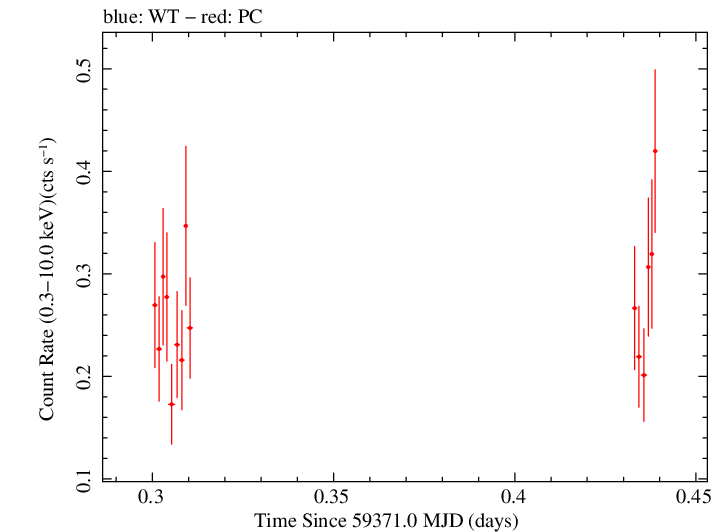
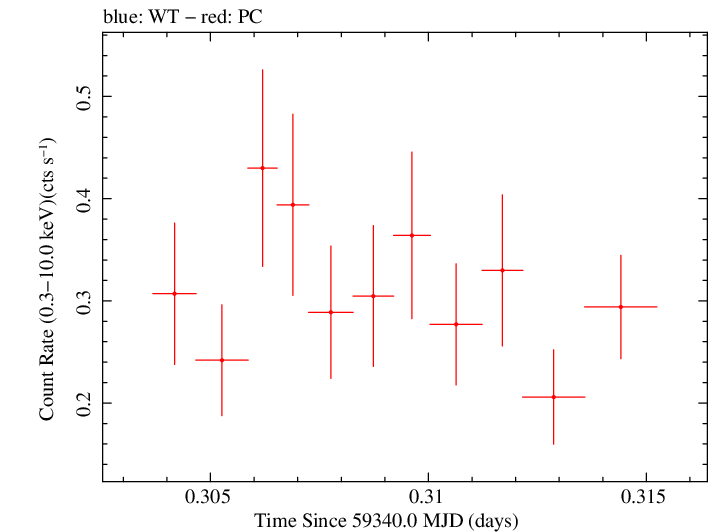
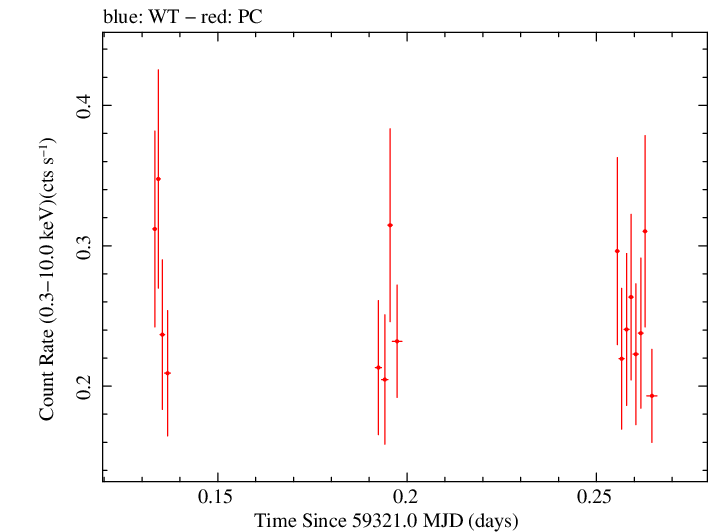
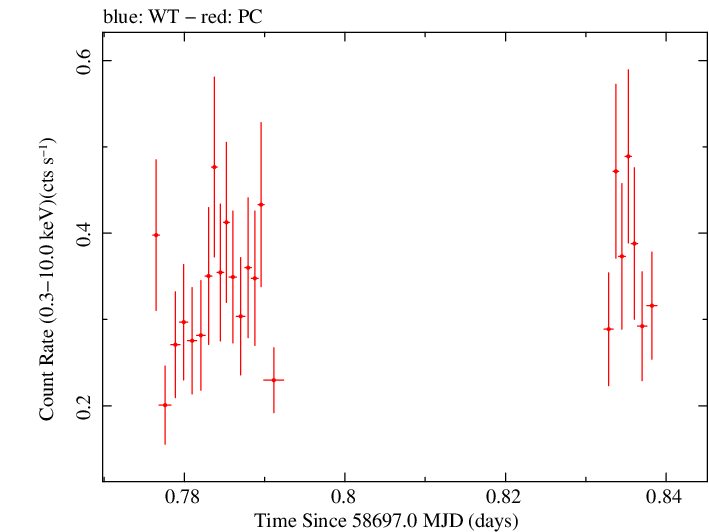
Linear Light Curve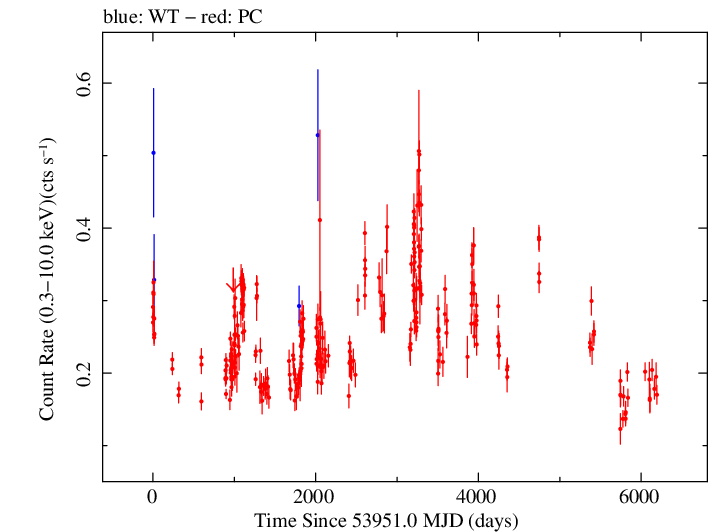 |
Log Light Curve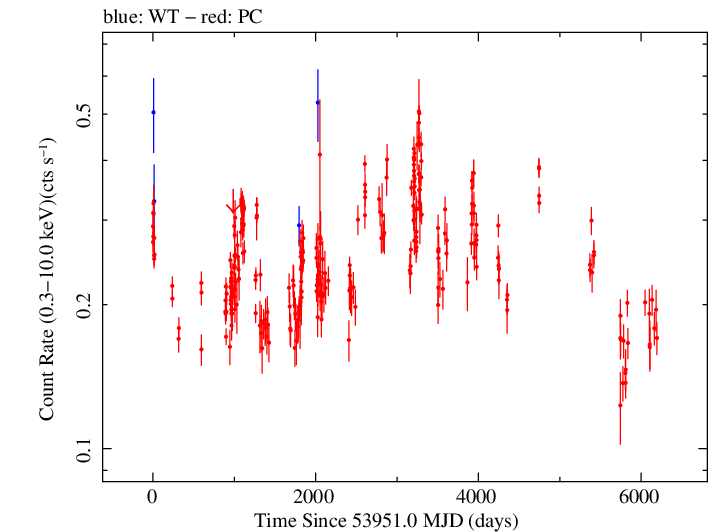 |
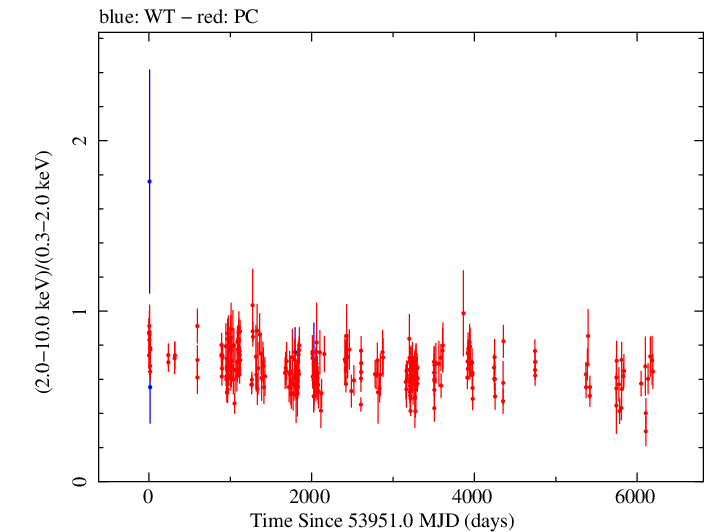
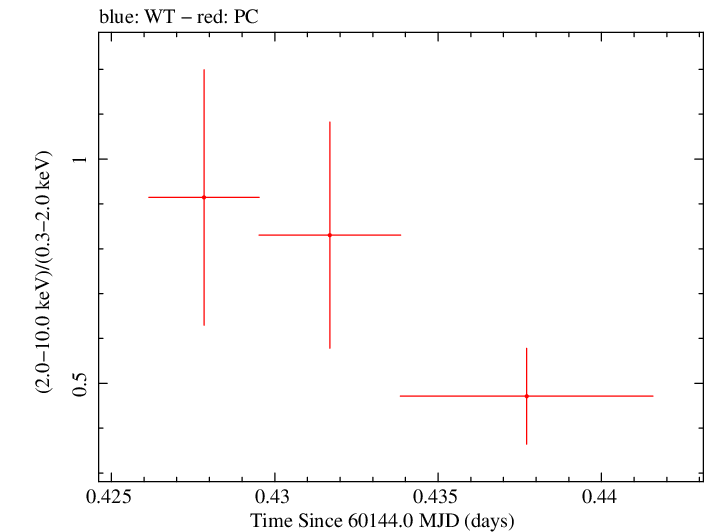
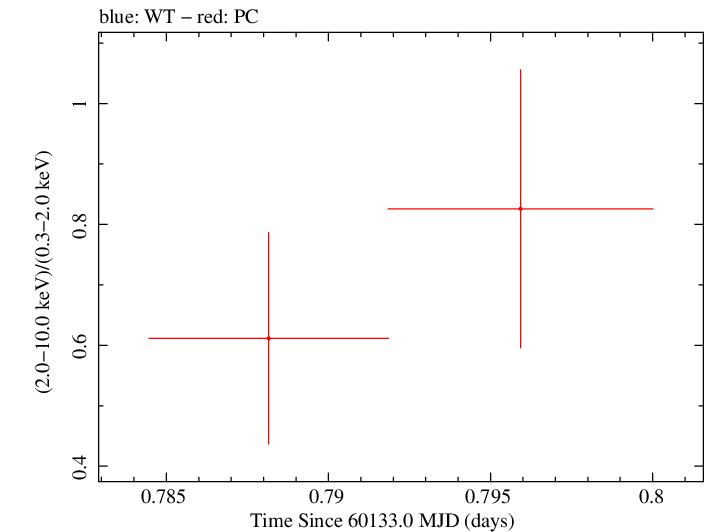
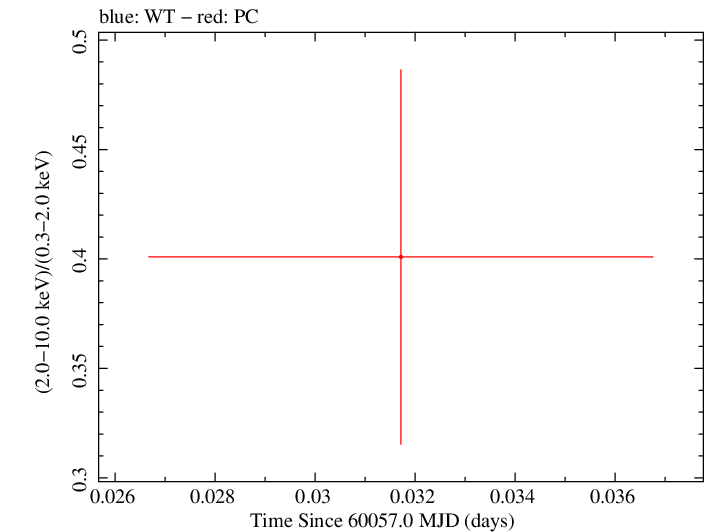
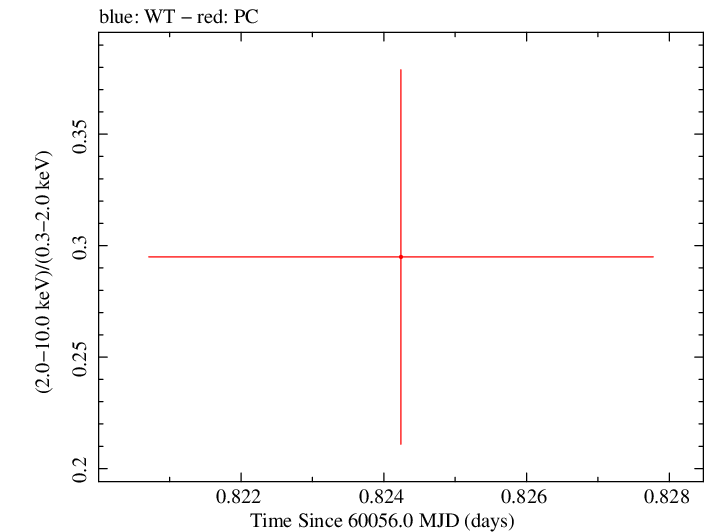
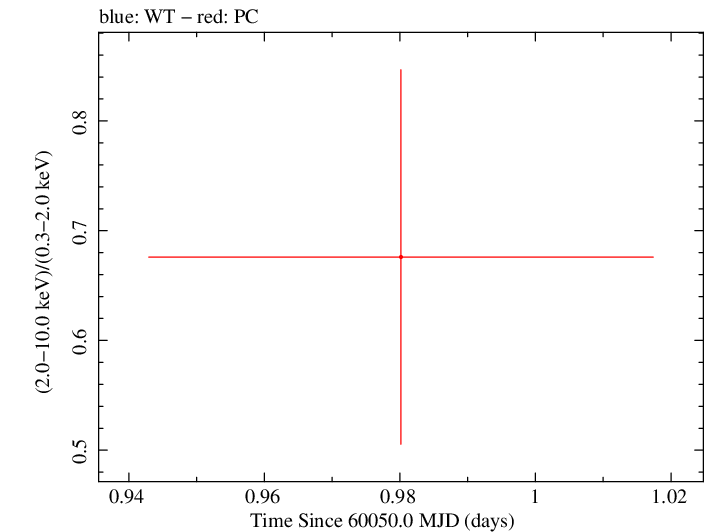
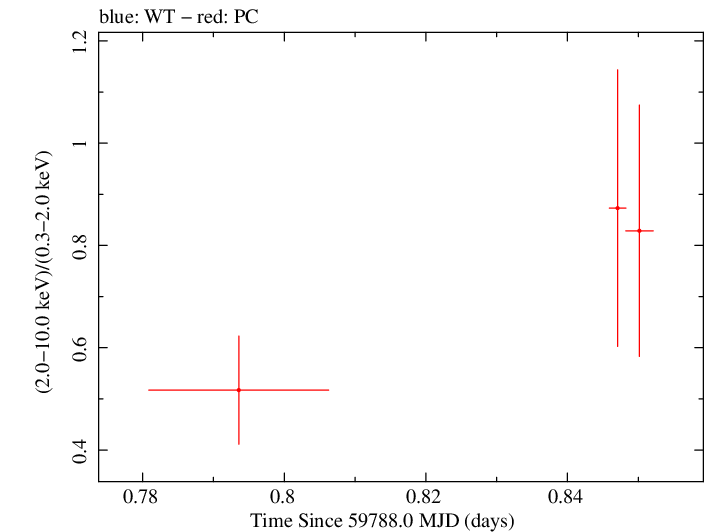
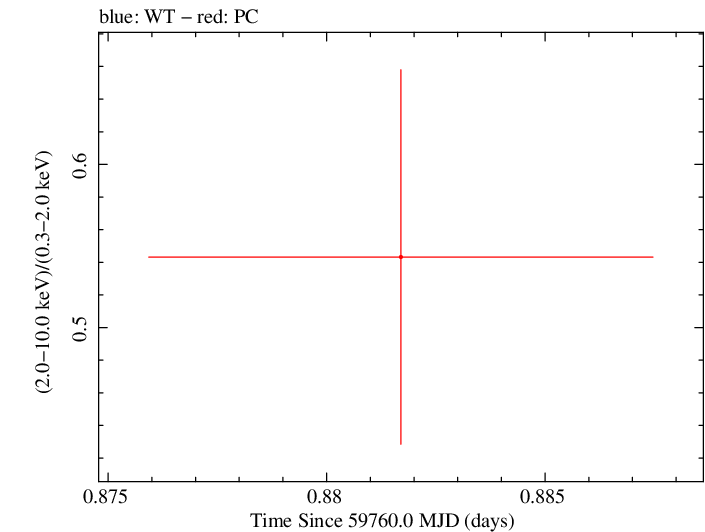
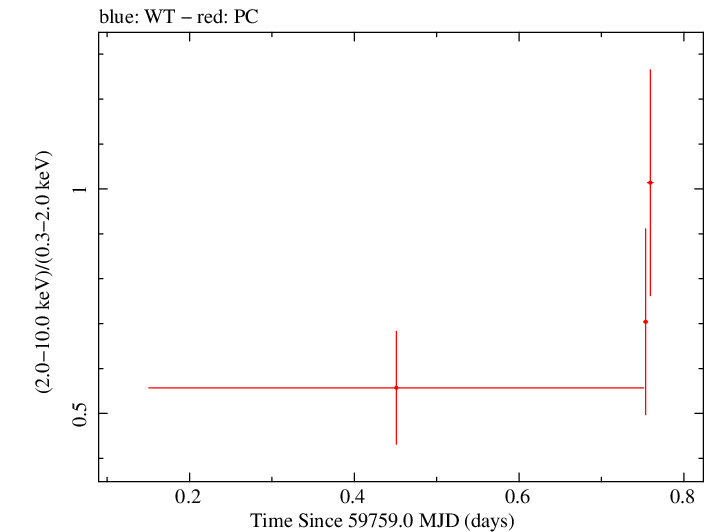
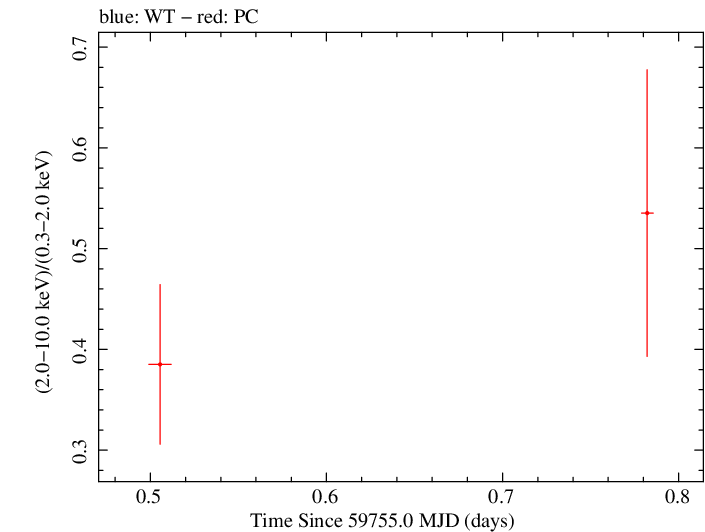
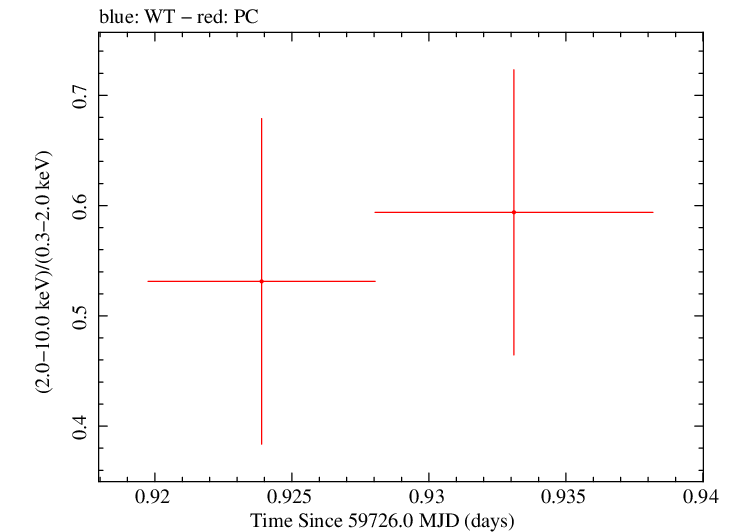
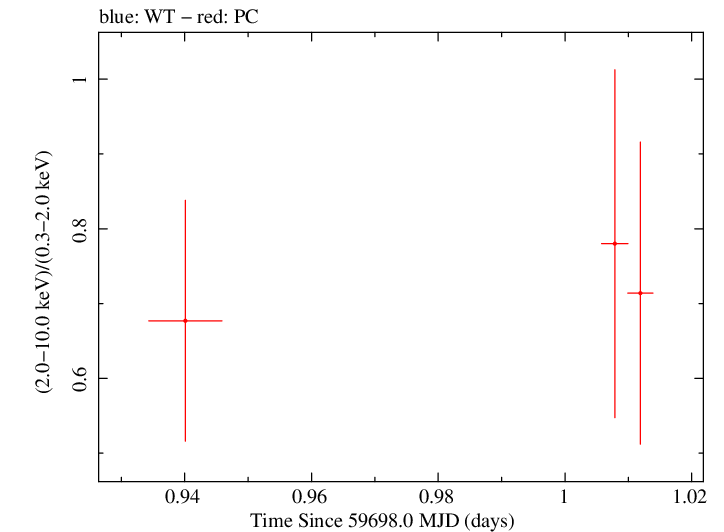
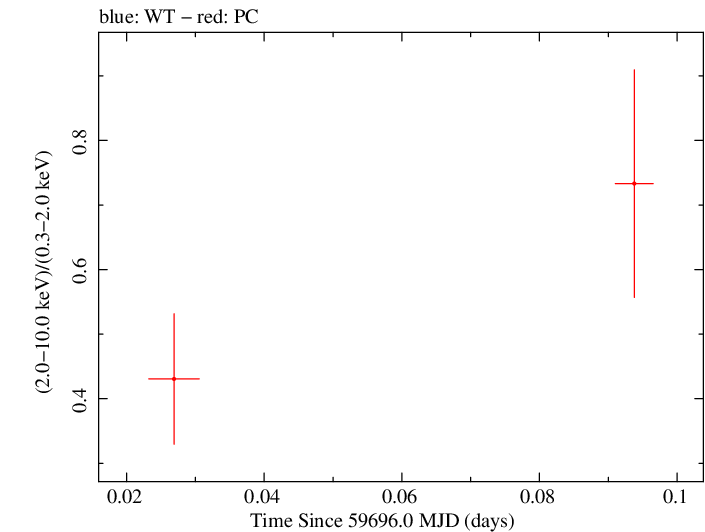
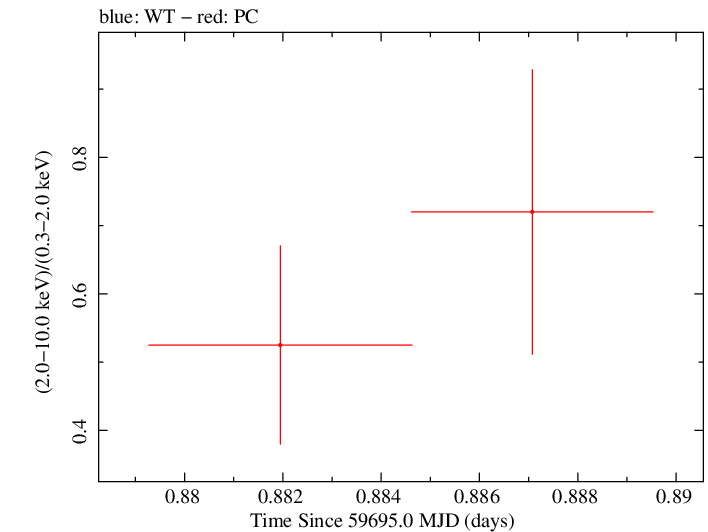
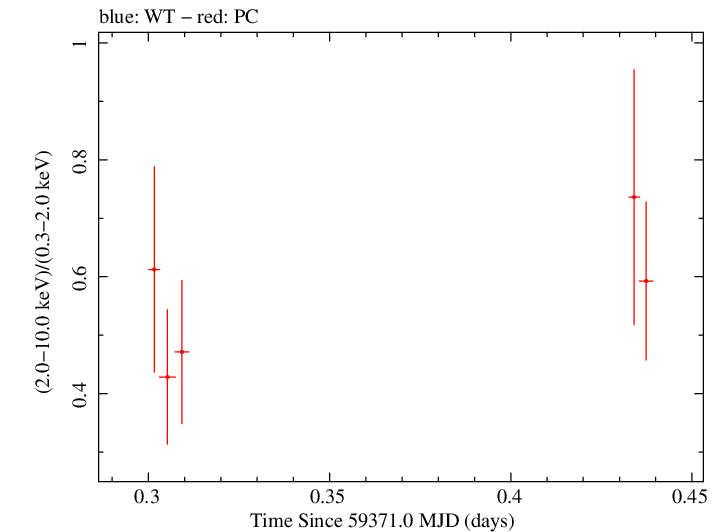
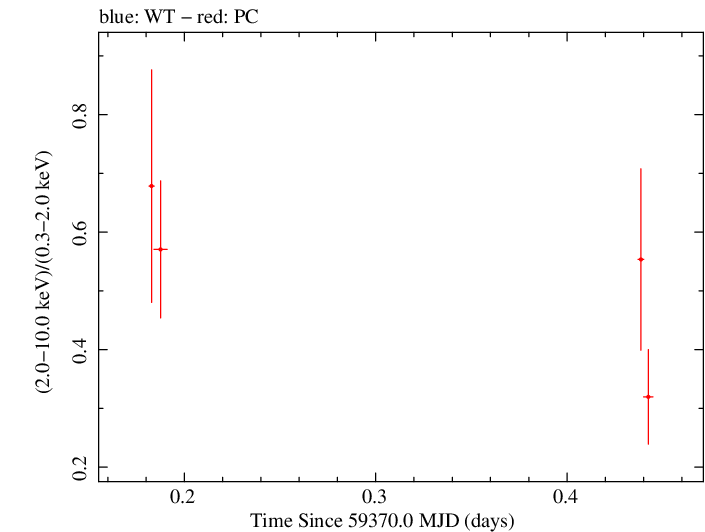
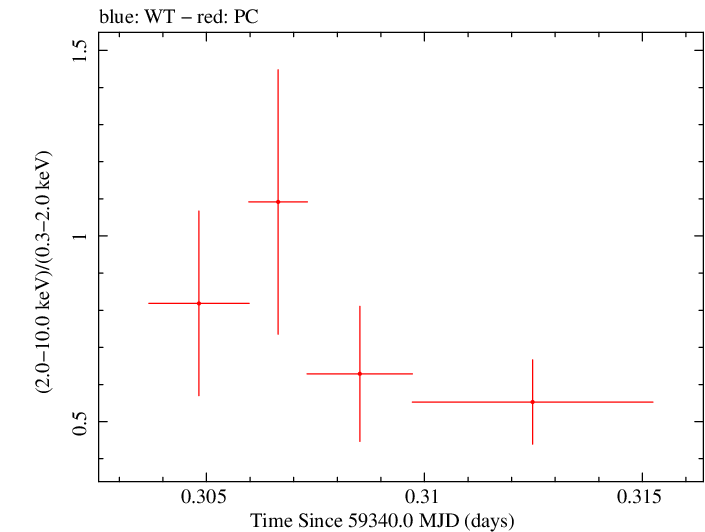
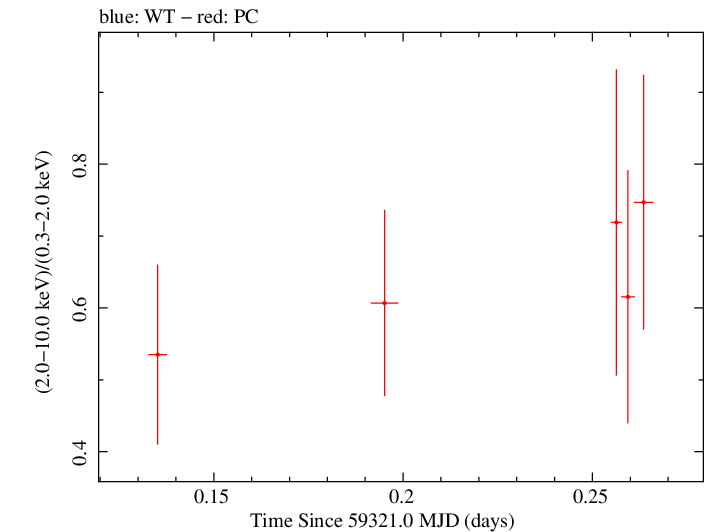
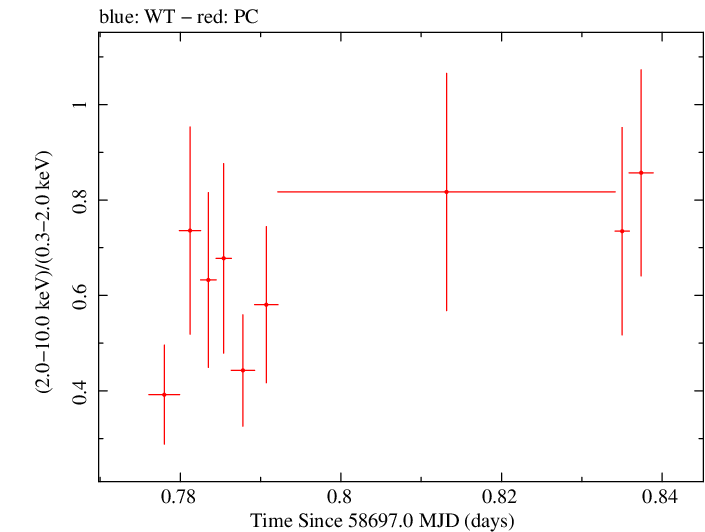
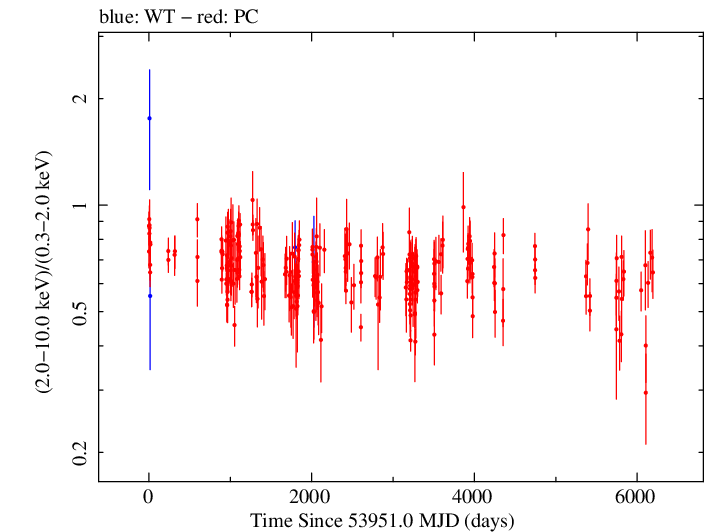
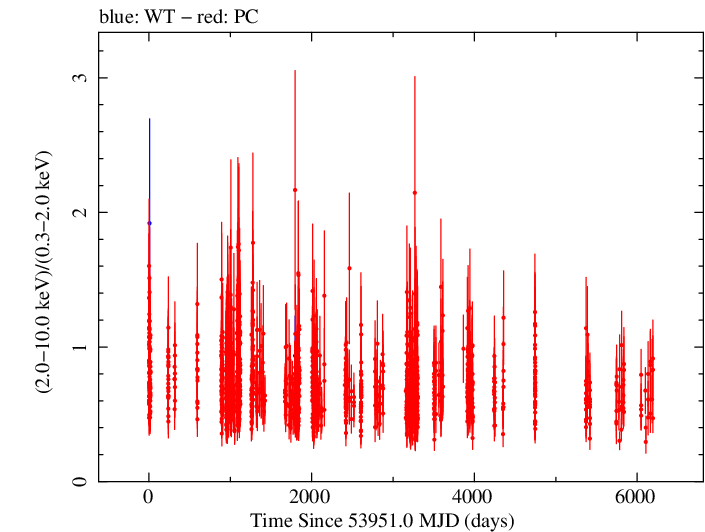
Overall Hardness Ratio
Overall Light Curve (png)|Overall Log Light Curve (png)|
Overall Hardness Ratio (png)|
Overall Log Hardness Ratio (png)
Overall Light Curve (txt)|Detailed Overall Light Curve (txt)|Overall Hardness Ratio (txt)
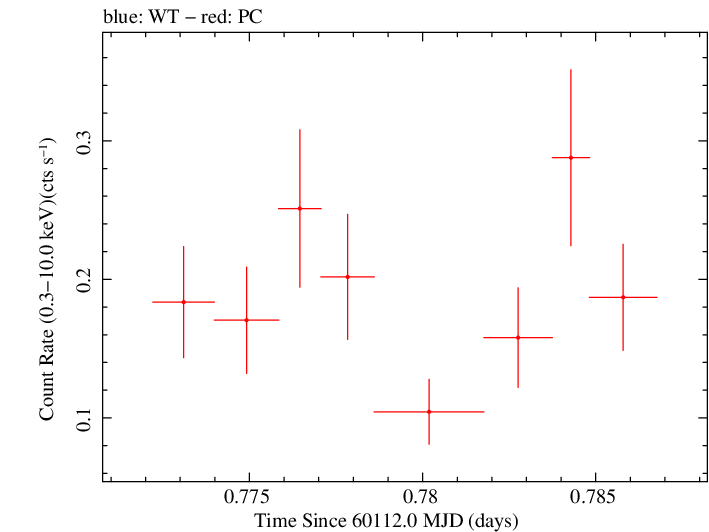
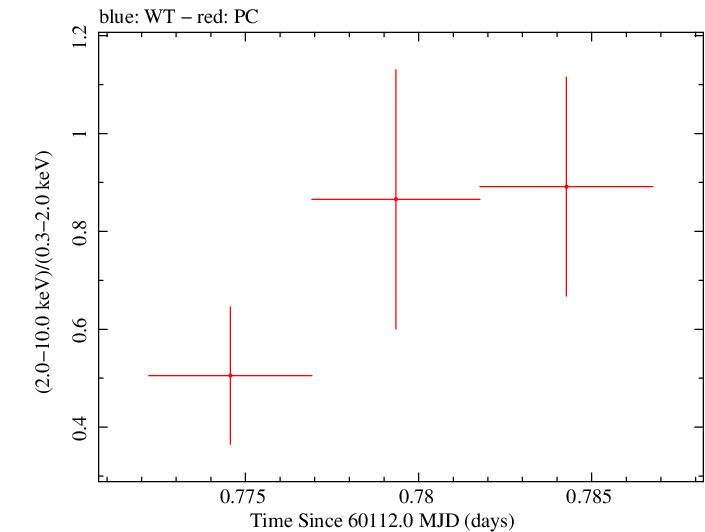
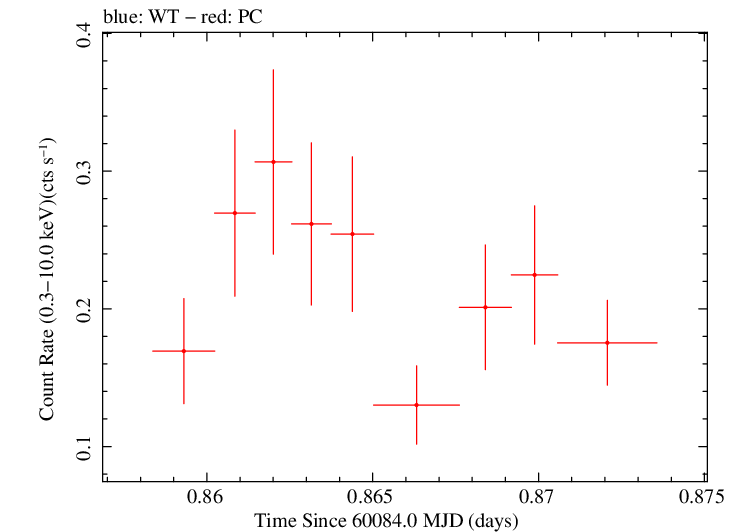
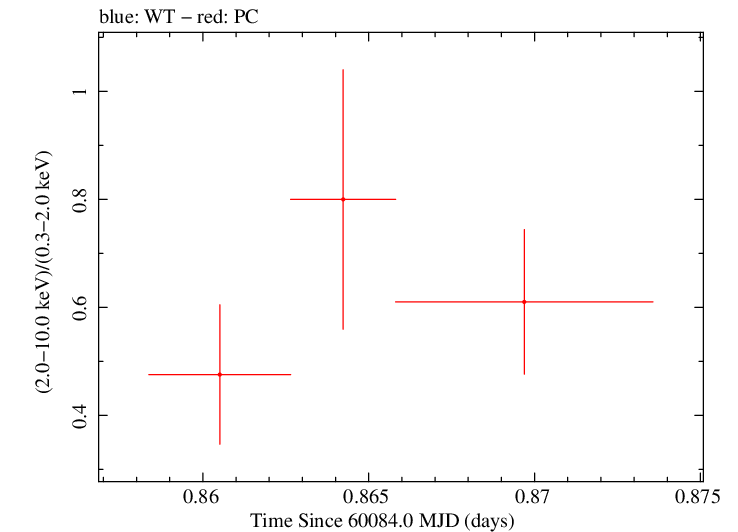
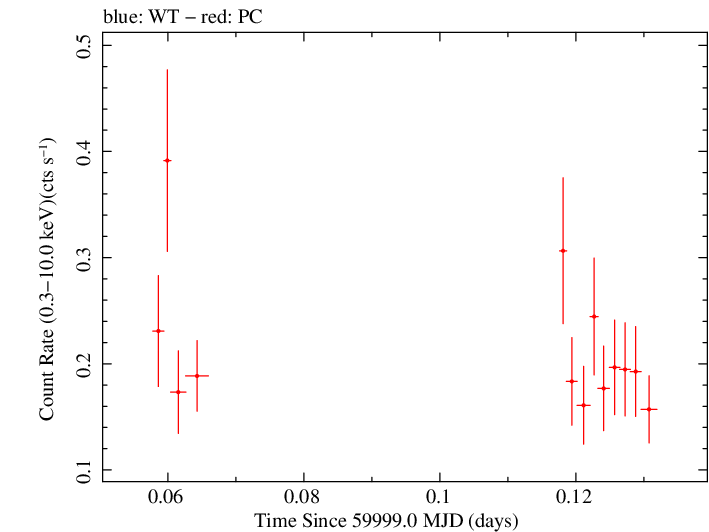
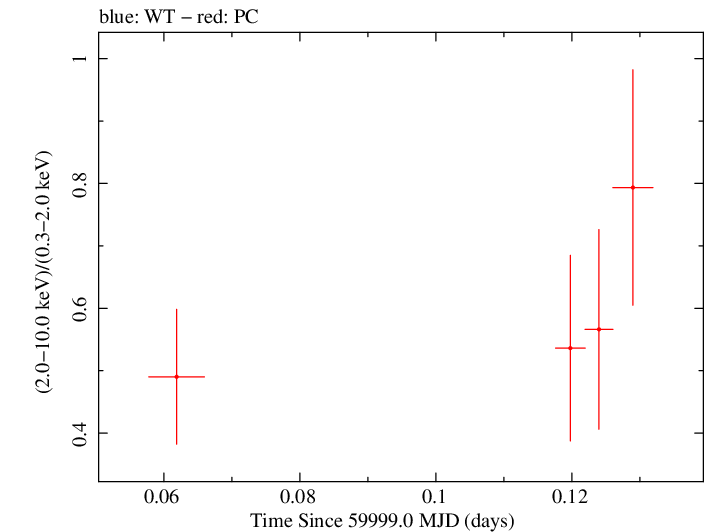
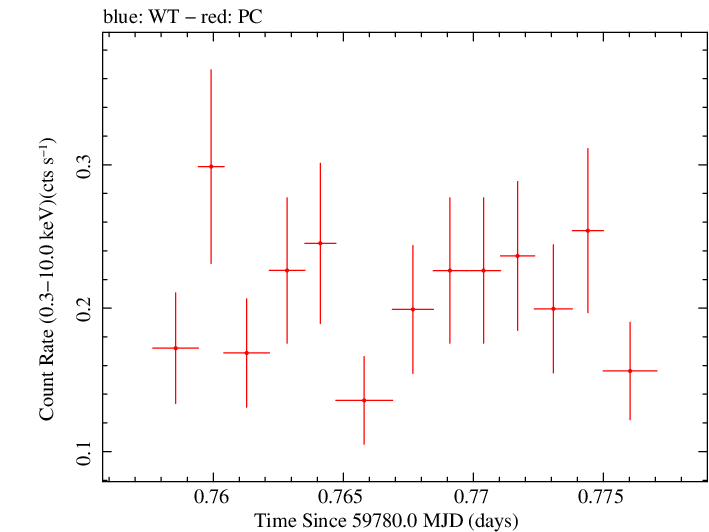
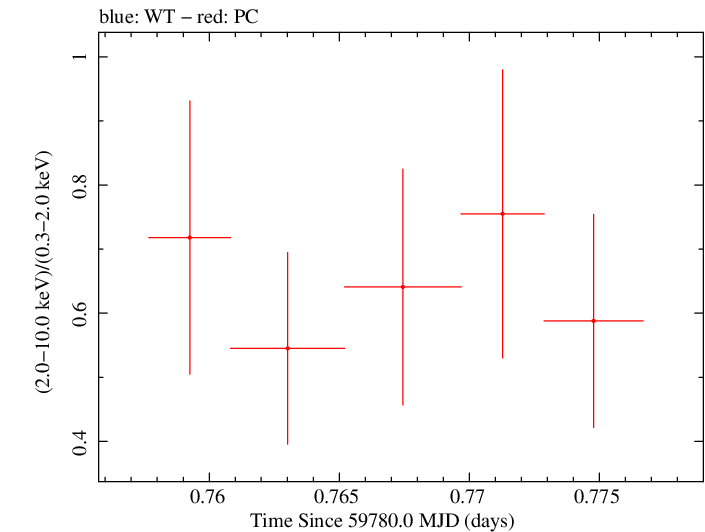
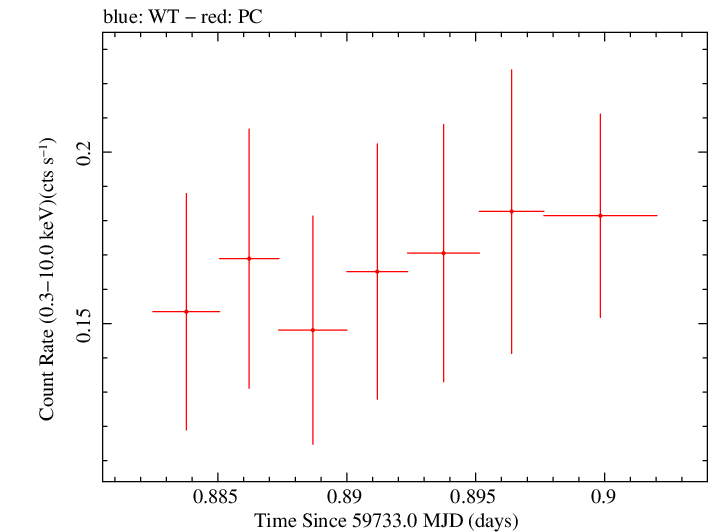
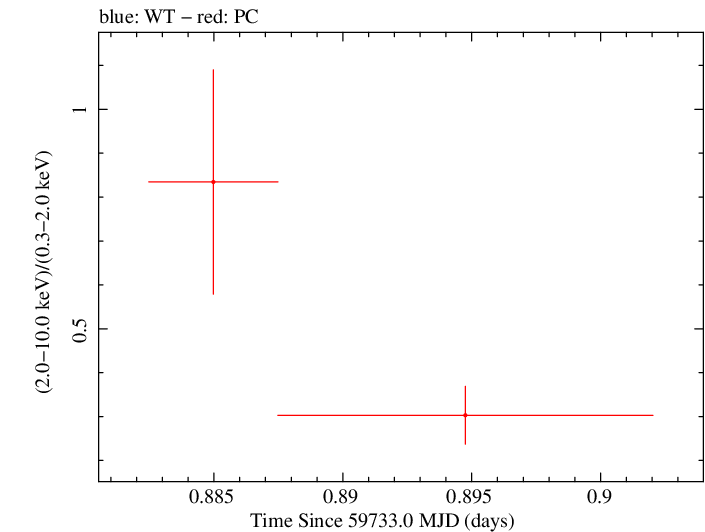
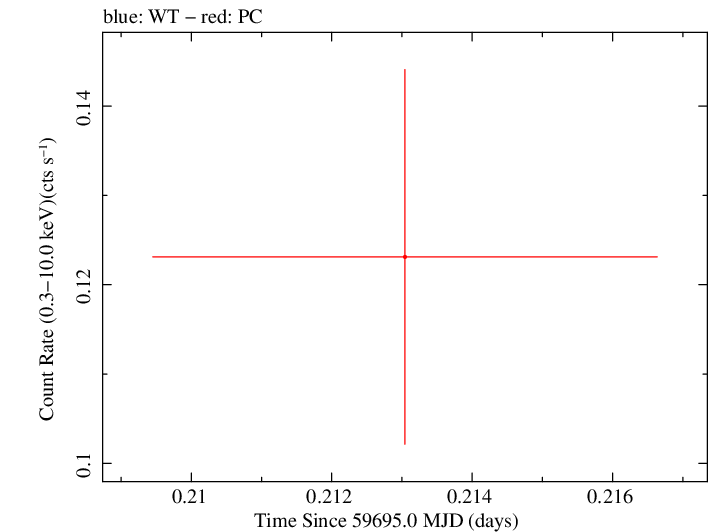
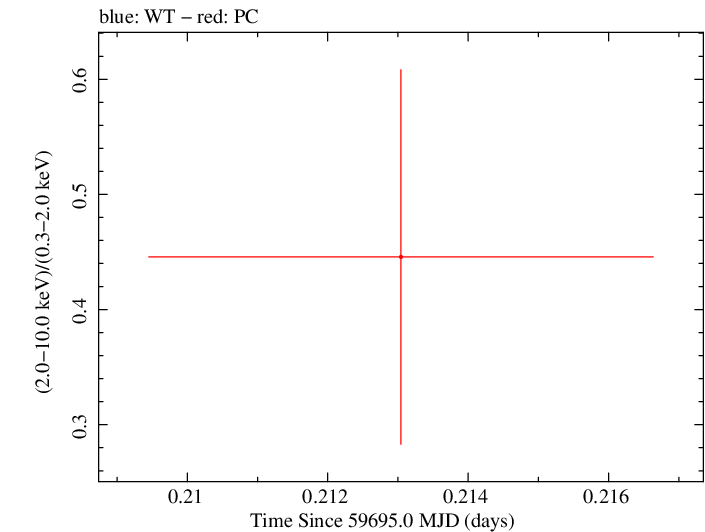
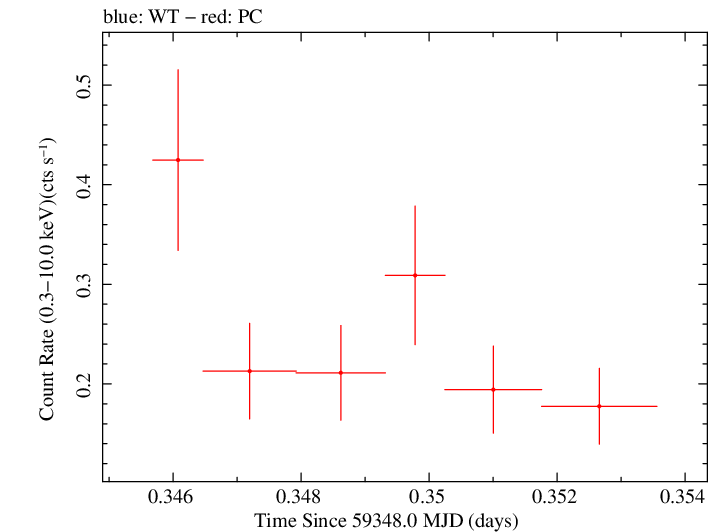
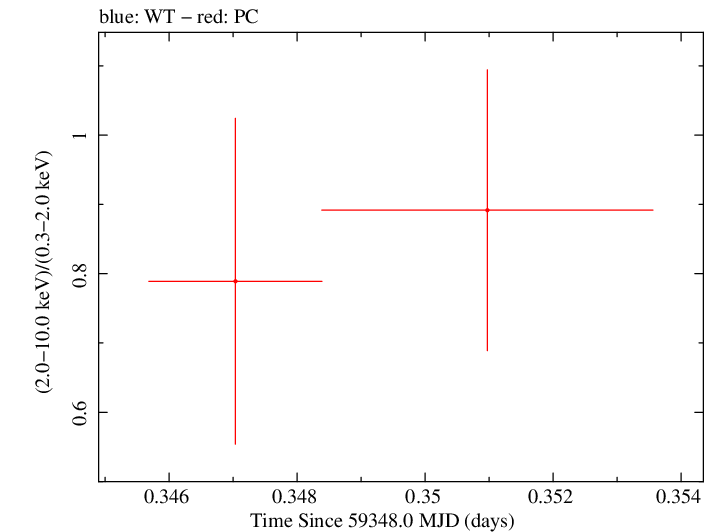
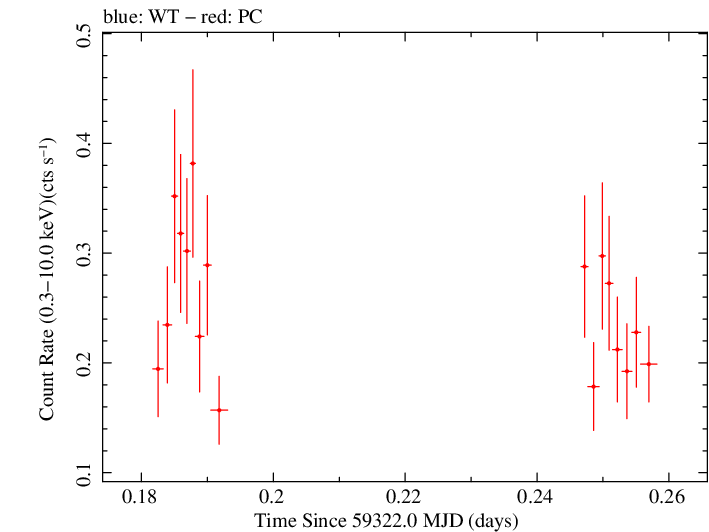
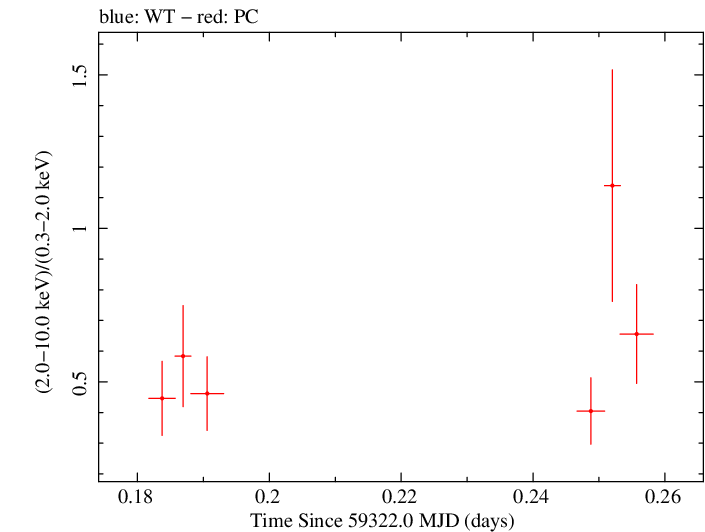
Finely Binned Light Curve (png)|Finely Binned Log Light Curve (png)| Finely Binned Hardness Ratio (png)| Finely Binned Log Hardness Ratio (png)
Finely Binned Light Curve (txt)|Detailed Finely Binned Light Curve (txt)|Finely Binned Hardness Ratio (txt)
Overall Light Curve (txt)|Detailed Overall Light Curve (txt)|Overall Hardness Ratio (txt)
Finely Binned Light Curve (png)|Finely Binned Log Light Curve (png)| Finely Binned Hardness Ratio (png)| Finely Binned Log Hardness Ratio (png)
Finely Binned Light Curve (txt)|Detailed Finely Binned Light Curve (txt)|Finely Binned Hardness Ratio (txt)



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}